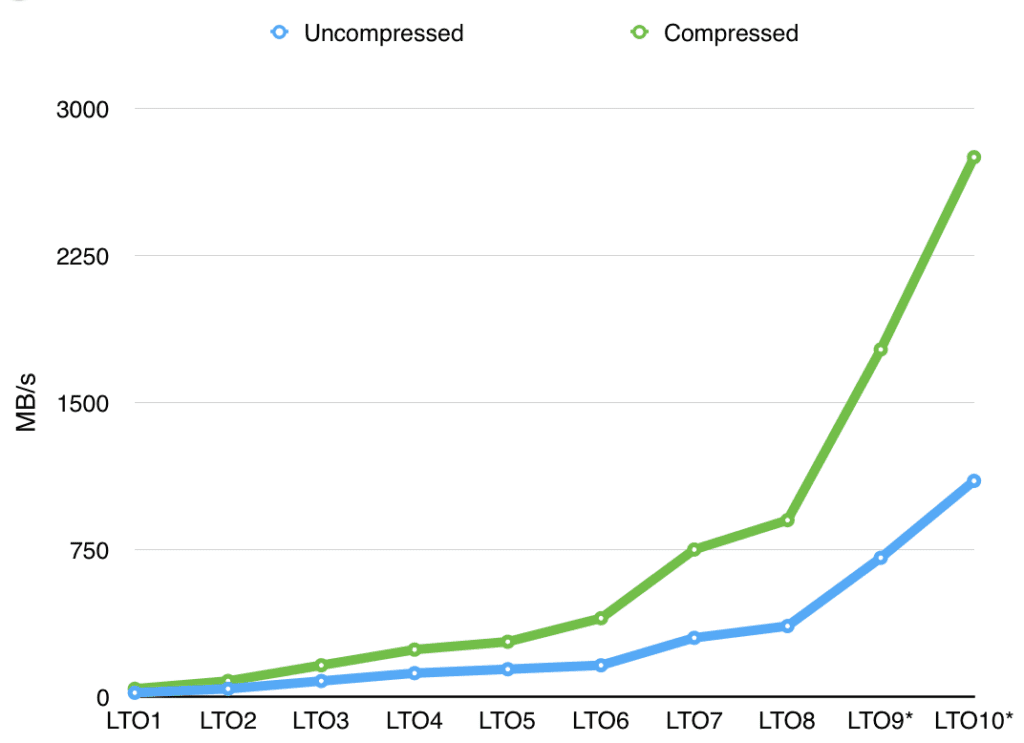
The current generation of LTO is LTO8, with a native speed of 360MB/s and a peak speed of 900MB/s. This doesn’t sound slow at all! For comparison, Seagate has announced their fastest drive ever using multi actuator technology at 480MB/s. More typical hard drive performance is in the 100-250 MB/s range these days. So why does tape have a reputation for being slow? To understand this, we need to look at a several factors. The streaming performance of tape is very high, but it takes time to position the tape media to the required location (called an offset) to read a given file. The current generation LTO media is a reel of magnetic tape that is approximately 1 kilometer in length. This means it can take some time to spin the reels to get to the offset that is needed. For LTO8, the average locate time (time to position the media from the beginning of the tape to the middle of the tape) is 60 seconds. But even this isn’t the whole story. The tape cartridge might be in a tape library slot instead of already loaded in a drive. The time for a library to move the cartridge from the slot into the drive can vary by library vendor, library size, number of robotic units within the library, and slot position within the library. But generally it takes about 10 seconds for the robot to grab the tape media and place it in a drive. The drive can then take another 15 seconds to load the media and be ready to accept commands. This is all assuming there is an available tape drive for the tape media and that the robot is not already busy moving other cartridges around the library.
As an interesting side note, LTO8 uses 4 data bands per tape, and 52 wraps per band. This means that it takes 208 end to end passes to write a full piece of tape media. That’s about 124 miles worth of tape! An LTO8 drive can write the full media (uncompressed) in about 9.25 hours. That equates to an average tape speed of about 13.4 mph while writing, and almost 18 mph while positioning.
Okay, back to positioning times. Let’s compare all of this to an enterprise capacity disk drive (I am using the Seagate ST4000NM0004 specs for this). The average latency is 4.16ms for this disk. And for typical uses, there is no load or move time for disk drives since they are generally connected and online in the server. This means that moving the disk head to the required sector is over 20,000 times faster than loading and positioning the tape media, and this is pretty much the best case scenario. Things gets much worse on a busy system if we need to wait for an available tape drive.
Tape and Workflows
Now we can start to see where tape has earned a reputation for being slow. But is there anything we can do about this? Maybe, but we need a better understanding of workflows to answer this question. It’s clear that if the workflow is just frequent random access, then disk systems will be far superior. However, frequent random access is not the typical access pattern for a large data archive.
“…frequent random access is not the typical access pattern for a large data archive.”
When a user needs to retrieve data from a large archive, it might be typical that they need many files associated with a single dataset. The files might be associated by time written, file path, owner, size, or other attribute. Or similarly, the archive might be accessed simultaneously by many users requesting many files. In all of these cases, the data offsets are not strictly random. There is generally a group of data in the form of a larger file or many small files that are requested together. And when writing data to the archive, it is more typical to see entire files or datasets written at the same time instead of smaller random updates to individual files. This is because frequent small updates to files are generally occurring while the file is still located on the tier 1 enterprise NAS system. Archives tend to see updates in the form of periodic batch jobs to sync files, or user driven archiving of larger data sets that are no longer frequently changing.
It is common in all kinds of data storage systems to see faster storage that is more expensive paired in a system with slower storage that is cheaper. There is a performance vs. capacity cost tradeoff. This tradeoff is seen at many different layers from CPU registers, to CPU cache, to main memory, to solid state disk, to disk drives, and to tape. We do not generally see a faster layer completely replace a slower layer, but instead we see the faster layers utilized as a cache for the slower layers, recognizing that access patterns do not require the entire storage capacity to be fast.
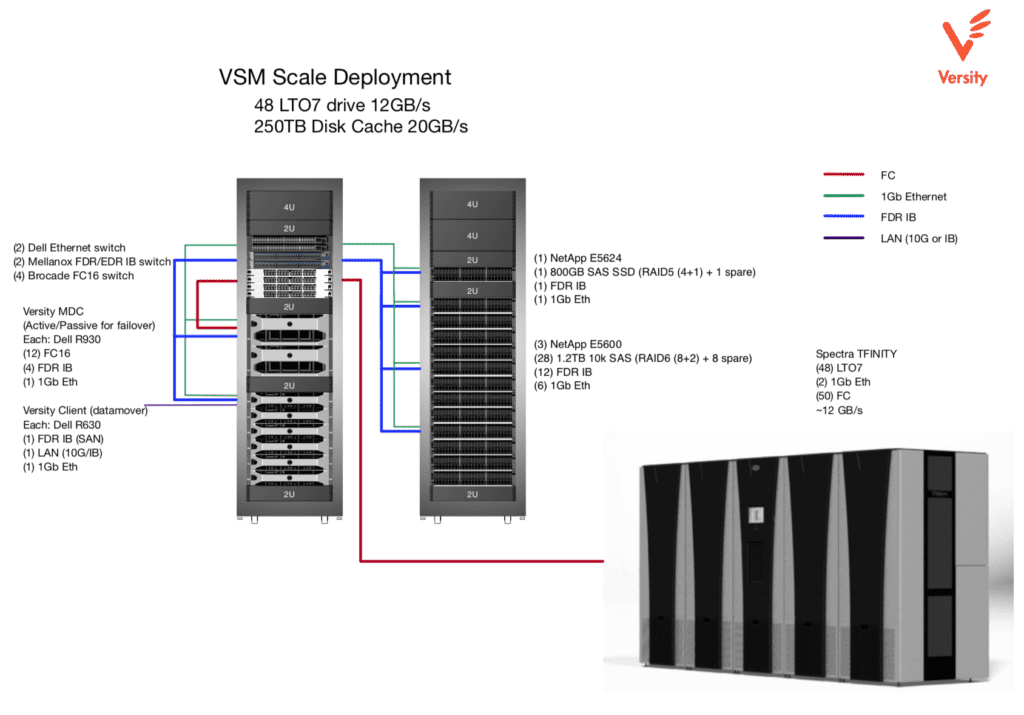
In large high performance tape archive systems, we implement a disk cache in front of the archival storage media. The system of disks in front of the tape system functions as a high performance cache for both read and write to the archive. If the disk system is sized correctly, writes to the archive will not need to wait for a piece of tape media to load. Instead, the user can complete the writes to disk and the archive software can asynchronously schedule that data to be written to tape at a later time when the tape is ready and at the required offset. Similarly, on read we do not need to wait for the user to request every byte of data before starting to retrieve data from tape. If we have a queue of file requests for a given piece of media, then the archive scheduler can sort the queue based on media offset and orchestrate a single pass down the tape reading all requested data from that media and writing it to the disk cache. Once a data set is complete, the user can access the data directly from disk cache.
Disk that can’t keep up with tape?!?
So now assuming we can put together a system that can do all of the above, we still have the problem that the tape streaming performance is much faster than single drives in our disk cache. The solution here is to simultaneously stripe data across multiple drives using some sort of RAID setup. Since this is an enterprise system, we probably don’t want the cache to fail with individual disk failures. So a RAID mode with some data protection in addition to data striping would be appropriate here. With drive capacities so large these days, it is more common to pick a double parity scheme because the time it takes to rebuild the RAID set is so long that the risk of another disk failure is too high for many enterprise applications. So RAID6 is the common deployment strategy for a system such as the one we are designing. Robin Harris has some interesting insights on how long RAID6 will continue to be a viable configuration in a recent blog post but it is beyond the scope of this discussion.
This RAID configuration allows us to stripe data across several disks and have two redundant disks in case of failures. Many RAID controllers have a performance sweet spot around 8+2, meaning we are getting the performance of striping data across eight drives while getting the reliability of two extra drives. With eight times the performance of a single drive, this RAID setup should deliver the performance we need to keep the streaming tape devices utilized. However, this is not the entire performance story.
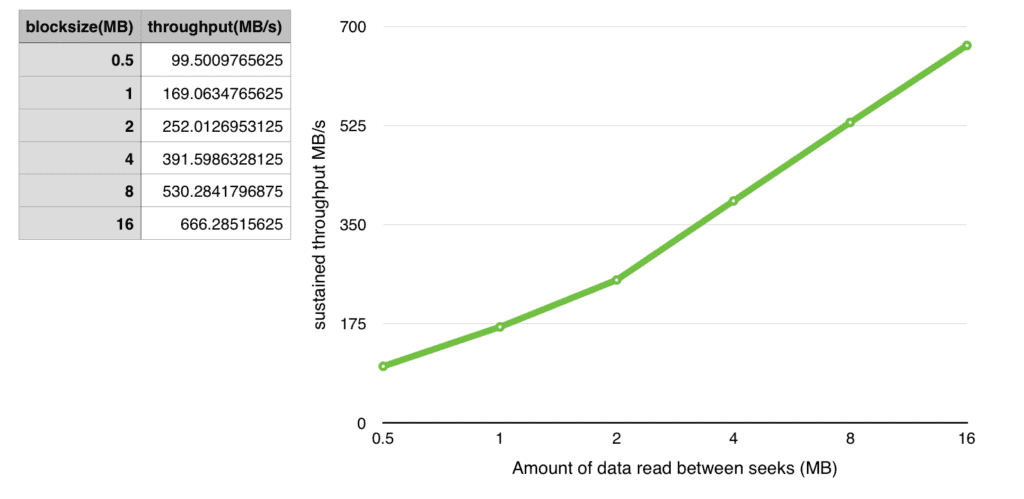
As we saw before, the seek times for disks are fast but not negligible. Too much seeking with small amounts of data read/written at each location will compromise the performance level we need out of the drives. Let’s take a look at some worst case scenarios here.
This benchmark is using a NetApp E5500 RAID controller and 10x 800GB SAS 10k RPM disk drives configured in RAID0.