Enhancing End-to-End Data Integrity in ScoutAM with User-Supplied Checksums
Ensuring data integrity is at the heart of modern archival systems, especially for organizations managing critical or large-scale data workflows. […]

As data volumes continue to grow exponentially, organizations must carefully consider how they manage storage resources. Many rely on various archiving systems to balance performance, cost, and capacity by automatically moving data between high-performance primary storage and lower-cost archival storage.
Within this framework, two distinct archiving models emerge: implicit archiving and explicit archiving. The implicit model transfers data to archival storage automatically, often without user awareness, while the explicit model requires users to make deliberate decisions about which data should be archived. These approaches differ significantly in their impact on system performance, data accessibility, and long-term storage efficiency.
This article explores the key differences between these two models, highlighting the challenges of implicit archiving and the benefits of adopting an explicit approach.
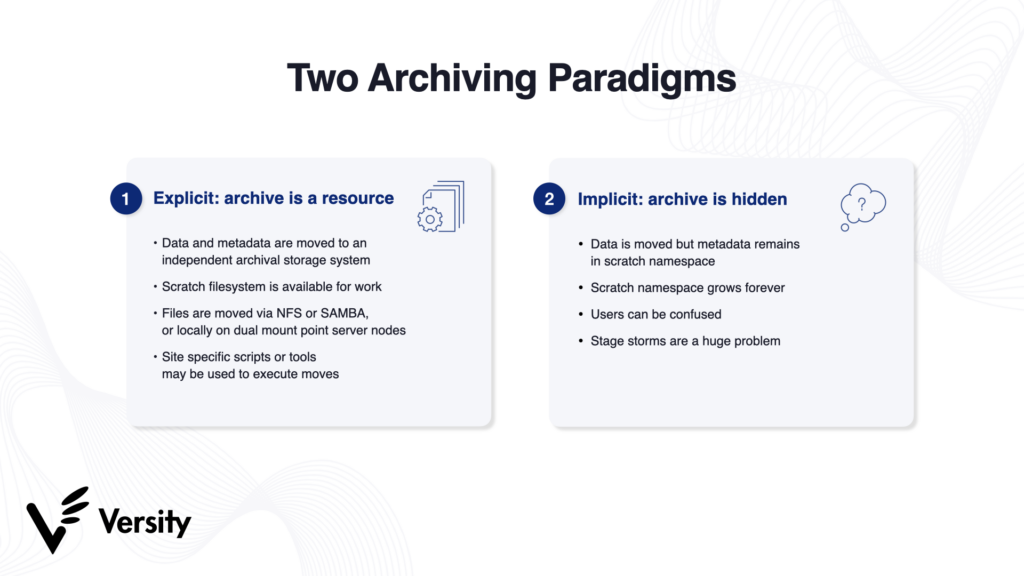
The implicit archiving model operates in the background, moving data to an archive based on predefined rules. While this approach may seem convenient, it introduces several challenges that can complicate long-term data management.
One of the defining characteristics of implicit archiving is that the archive cannot function as a standalone resource. Although data is moved to archival storage, its metadata remains in the primary filesystem’s scratch namespace. This means that users must interact with the primary filesystem to retrieve archived data, preventing the archive from being used independently.
This tight integration creates dependencies between the two storage systems. If the primary filesystem fails or becomes unavailable, access to the archive is also disrupted. Organizations that need to maintain long-term archives—especially for compliance, research, or legal purposes—may find this restriction problematic, as archived data should ideally be retrievable even if the primary filesystem is decommissioned or replaced.
Since metadata remains in the scratch namespace even after data is archived, the primary filesystem continues to grow indefinitely. This unbounded accumulation of metadata can lead to severe performance degradation over time.
Because the archive and primary filesystem are deeply interconnected, organizations are often locked into using a single vendor for both solutions. This dependency limits flexibility in several ways:
A recent example of vendor lock-in’s impact is the UK government’s experience, where reliance on major cloud providers like AWS and Azure has inhibited its negotiating power over cloud services. The Cabinet Office’s Central Digital & Data Office acknowledged that this dependency could lead to minimal leverage over pricing and product options, potentially resulting in entrenched vendor lock-in and regulatory scrutiny.
Implicit archiving often results in a lack of transparency for users, who may not be aware of whether a given file is stored on primary storage (online) or archived (offline). This can lead to several unintended consequences:
Because implicit archiving operates automatically, data that may not be needed or useful can end up in archival storage. When data is automatically archived without careful selection, unnecessary files accumulate in the archive, consuming valuable space and driving up costs over time.
Furthermore, organizations often struggle to clearly determine what is stored in their archive and whether the archived data remains relevant. This lack of clarity can result in inefficiencies during audits, compliance checks, and long-term data retrieval efforts, ultimately complicating overall data management and potentially impacting operational effectiveness.
The explicit archiving model offers a more structured and user-driven approach to storage management. Unlike the implicit model, where data is moved automatically, the explicit model requires users or administrators to make deliberate decisions about what to archive and when. This ensures that only relevant data is preserved while reducing unnecessary storage consumption.
By involving users directly in the archiving process, the explicit model fosters better organization and awareness. Users gain a clear understanding of access requirements and retrieval expectations because they intentionally choose what to store. This results in:
A key advantage of explicit archiving is that the archive operates as an independent resource rather than being tied to the primary filesystem. This separation provides several benefits:
One of the most significant drawbacks of implicit archiving is the risk of vendor lock-in. Since implicit models tightly integrate the archive with the primary storage, organizations often find themselves stuck with a single vendor’s ecosystem. Explicit archiving eliminates this issue by keeping the two systems separate.
When the primary storage and archive operate independently, organizations have the flexibility to upgrade or replace storage systems without disrupting access to archived data. If the primary filesystem reaches the end of its lifecycle, organizations can transition to a new system without worrying about losing access to archived data.
This decoupling also opens up competitive bidding opportunities, as archive solutions can be evaluated separately from primary storage. The result is a more adaptable storage infrastructure where organizations can select best-in-class solutions that meet their evolving needs
With explicit archiving, files are stored in a clearly defined archival system, making data retrieval more transparent and efficient. Organizations can use various methods to move and access files, including:
While implicit archiving may seem convenient due to its automation, its hidden nature and tight coupling with the primary filesystem create numerous challenges, including performance degradation, vendor lock-in, and a lack of transparency for users. In contrast, the explicit archiving model offers a more deliberate and organized approach, promoting better storage efficiency, system reliability, and flexibility in vendor selection.
Organizations seeking to optimize their long-term data management strategy should carefully evaluate these models to ensure their storage infrastructure remains scalable, efficient, and adaptable to future needs.

Ensuring data integrity is at the heart of modern archival systems, especially for organizations managing critical or large-scale data workflows. […]

The Versity S3 Gateway’s stateless architecture transforms S3-compatible storage with unmatched scalability, resilience, and efficiency. Learn how it simplifies load balancing, enhances fault tolerance, and adapts seamlessly to any infrastructure.

Discover how NIWA, New Zealand’s leading environmental research institute, is safeguarding the future of the nation’s climate data by partnering with Versity. Learn why they chose Versity’s ScoutAM to modernize their vast weather archive, ensuring the long-term preservation and accessibility of critical environmental data. This article dives into the innovative approach that made Versity the ideal choice for this crucial modernization effort.

Connect with Versity today to find out how we can tailor a solution to keep your organization’s data safe and accessible as you advance your mission.